Architecture
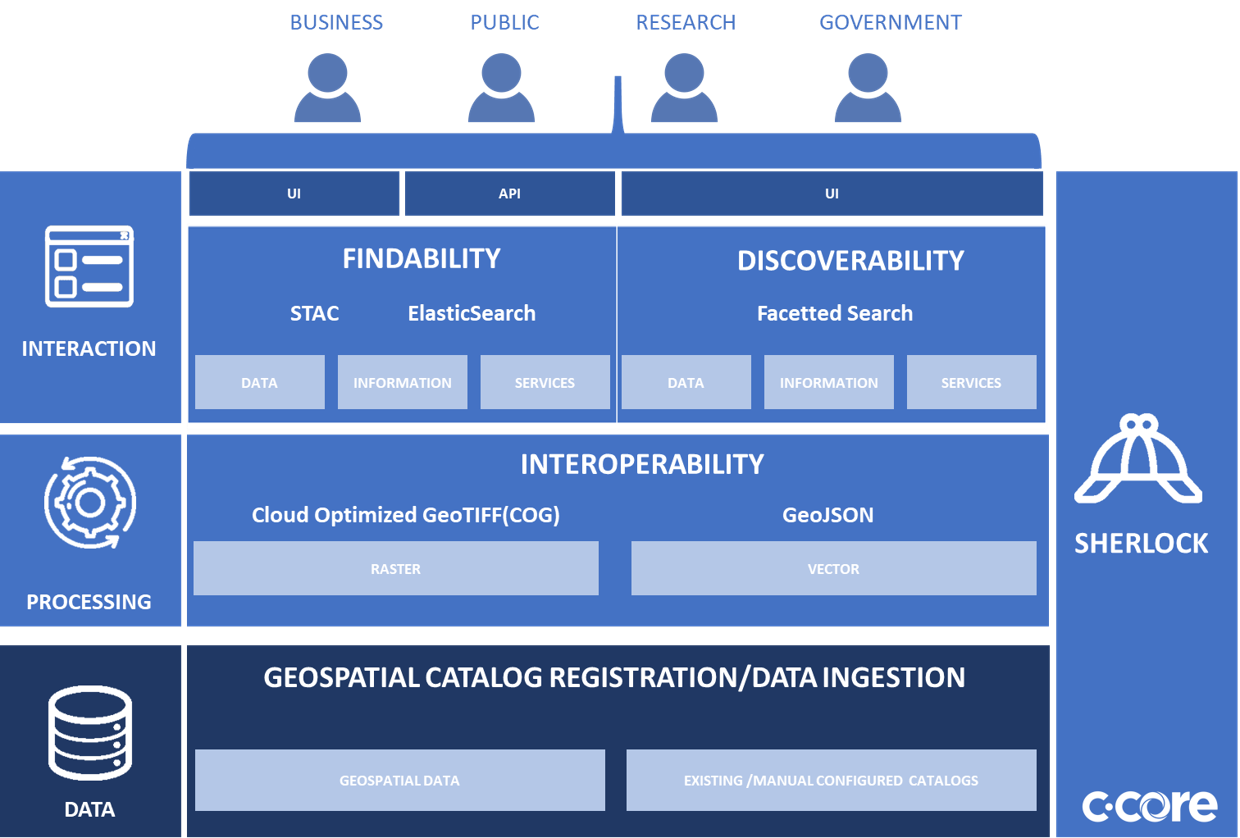
Infrastructure#
Elastic Instances#
Elastic search was chosen for the indexing and enabling of search capabilities. For the hosting of the Elastic data stores a managed solution was chosen. Appbase.io was chosen as costing was lower than running a self maintained cluster on AWS. Additionally Appbase provides a built in data browser, and search analytics as part of their packages.
| Location | Package | Nodes | CPU | Memory | Storage | Cost |
|---|---|---|---|---|---|---|
| appbase.io | Sandbox | 1 | 2 | 4 GB | 30 GB | $49 |
| appbase.io | Starter | 3 | 2 | 4 GB | 40 GB | $149 |
| appbase.io | Production | 3 | 4 | 16 GB | 480 GB | $799 |
| appbase.io | Production | 3 | 16 | 64 GB | 999 GB | $3199 |
| AWS elastic search | t2.medium.elasticsearch | 1 | 2 | 4 GB | 30 GB | $110.30 |
| AWS elastic search | t2.medium.elasticsearch x 3 | 3 | 2 | 4 GB | 40 GB | $233.30 |
| AWS elastic search | m4.xlarge.elasticsearch x 3 | 3 | 4 | 16 GB | 480 GB | $865.10 |
| AWS elastic search | m4.4xlarge.elasticsearch x 3 | 3 | 16 | 64 GB | 999 GB | $2,970.36 |
Search API/ Ingest API/ Container Curation API#
Google Cloudrun was chosen as the hosting infrastructure. The core benefits of utilizing Cloud Run are:
- Automatic Scaling of instances
- No overhead for idle server due to scaling to zero
- Container based infrastructure
- Reasonable Cold start time.
Container Hosting#
For the curated hosting of containers, AWS Elastic Container Registry (ECS) was chosen. ECS allows for the hosting of private containers, that can then be made available to authenticated users. This solution was chosen as it C-CORE is currently hosting it's own images on ECR and the system is generally understood.
Authentication System#
AWS Cognito is chosen as the authentication and authorization service of choice. Cognito allows for Oath Token based authentication. Additionally Cognito allows for AWS IAM role based management which allows for general and fine grained user access across resources hosted on AWS.
Distribution of Source data#
It is the intent of this project ot provide the source for resources back to the open source community so it can be adapted and deployed by others. This open source library shall include the necessary resources to set up the ingest and search apis and run them in a container. Deployment should consist of building the container and supplying an config file with the necessary environmental variables to connect to the user hosted infrastructure.
Data Processing and Standards#
The Sherlock Irregulars Library is a library that has been developed in order to provide a workflow and engine for the creation of STAC items from various metadata sources.
Acquisition and cataloging will work to create STAC entries from external data sources. The STAC entries will then be pushed to the Elastic Data Store in order to be searchable.
Originally, the philosophy behind the Acquisition is to prefer to transform external metadata into a STAC entry on the fly, relying on the permanence of the hosted datasets. However this was then modified to include a permanent database solution host the STAC metadata, this was chosen so that we had a more reliable correlation between our Elastic hosted search indices and the STAC entries.
Submodules:
- External Reference to STAC
- Metadata Adapter Class
- Catalog
Data Adapter Class:
- Attribute Mappings for source metadata
- Geometry interpreter
- Asset attribute Format
- Item Tagging
Stac Entry factory:
- read external
- parse properties
- clean properties
- acquire geometry
- build stac reference
Catalog:
- push to elastic
Ingestion API#
Ingestion API Implementation
add item
- Add item will allow data to be pushed to elastic backend after passing validation check.
add collection
The ingestion API is built such that all Items will be part of a predefined collection. This is done for a number of reasons. The first is that each item loaded is assumed to come from an external archive and that association wants to be maintained. Secondly, having a collection registration process will allow for fine grained access to be introduced later if required. Finally requiring a collection to exist
validate record
- A validate method will be required to allow for a user to pre validate their stac entry before pushing it to the data store. This is purely a convenience as the function will be part of the core add item workflow as well. This check will check for valid STAC item as well as a collection that is currently enrolled in the platform.
batch add item
- Batch validation will be available to reduce number of calls that need to be made to the backend. This method will have to be fairy strict and will either accept all, or reject all and provide a list of failed validations by index (id would not work as missing id is a catchable error).
- Data Types
| Data Type | ? | ? |
|---|---|---|
| Sentinel-1 | ------- | ----- |
| OpenData | ------- | ----- |
Search API#
The Search part of Sherlock will be centralized around navigating a dynamic stac catalog. This will be powered by 2 APIs, the STAC api for querying and searching and the ingestion api for adding data to the data store. The apis will be hosted in docker containers and dockerfiles will be provided as part of the open sourced library. All configuration will be managed by an .env file, a template of which will be provided in the repo.
Recommendations#
Recommendations will be initially provided by using keyword relationships and geographic proximity. A ranking algorithm will be designed to provide the most similar products to the ones currently selected.
A simple recommendation algorithm will be generated that uses number of matched keywords as well as centroid distance to create rankings.algorithm. The use of centroid distance will work to prevent large extent datasets from dominating the search results.
API Features#
- Search API Implementation Specification
- / (Landing)
- conformance
- collections
- search
- items (features)
- items (single features)
- recommend
Authentication#
Authorization and Authentication will be done via Oath scopes retrieved using the AWS Cognito service. The sherlock platform will require users to either connect with email and password in the web application or using credentials in the Search API. An additional level of authorization will be used in the ingestion api to prevent unwanted addition of data to the catalog.
Search Portal#
sherlock-search.c-core.app
Consumer API#
The consumer api will extend the Search Api in order to allow access to the catalog from other applications.
Preprocessor Development#
Interoperability Curation Service#
The interoperability and curation service will allow for the hosting of special containerized applications for the transformation of hosted data into Analysis Ready Data. For rasters, this will involve any processing steps required to generate a COG from the source data. Each containerization will have an available link to a hosted image as well as the dockerfile needed to create the image from scratch. There will be a curation api that will display available containers as well as provide the ability to add or update entries.
- Interoperability API
- search
- list
- add
- remove